RDD
RDD,弹性分布式数据集(Resilient Distributed Dataset)是spark的核心概念,它是集群中跨多个机器分区存储的一个只读对象集合,弹性指spark可以通过重新安排计算来自动重建丢失的分区。在spark程序中,一般加载一个或多个RDD作为输入,通过一系列转换得到一组目标RDD,然后将这些RDD计算出结果或者写入持久存储器。
加载RDD或执行转换并不会立即触发任何数据处理的操作,只是创建一个计算计划。只有对RDD执行某个动作(如foreach)时,才会触发真正的计算。通过rdd的map()方法可以对RDD的每个元素应用某个函数,filter()方法的输入是一个过滤谓词,即返回布尔值的函数。
RDD 具有以下几个特点:
分布在集群中的只读对象集合,由多个 partition 构成,这些 partition 可能存储在不同机器上
RDD 可以存储在磁盘或内存中(多种存储级别),partition 可以全部存储在内存或磁盘上,也可以部分在内存中,部分在磁盘上
Spark 提供了大量 API 通过并行的方式构造和生成 RDD
失效后自动重构:Spark 通过记录 RDD 的血统,了解每个 RDD 的产生方式(包括父 RDD 以及计算方式),进而能够通过重算的方式构造因机器故障或磁盘损坏导致丢失的 RDD 数据
HDFS 的任何一个文件也可以认为是分布式数据集,但从一定程度上,HDFS 并不具有弹性,因为所有数据都存储在磁盘上。RDD 则可以将 Partition 部分存储在磁盘部分存储在内存。
转换和动作
转换(transformation)是从现有RDD生成新的RDD,动作(Action)触发对RDD的计算并对计算结果执行某种操作,要么返回给用户,要么保存到外部存储器中。动作的效果是立竿见影的,但转换不是,转换是惰性的,在对RDD执行一个动作之前不会为该RDD的任何转换操作采取实际行动。判断一个操作是转换还是动作,可以观察返回类型,如果返回的类型是RDD,那么它是一个转换,否则就是一个动作。
作业
Spark作业由任意多阶段(stages)有向无环图构成,有的阶段又被spark运行环境分解为多个任务(task),任务并行运行在分布于集群中的RDD分区上。作业始终运行在应用(application)上下文(SparkContext实例表示)中,它提供了RDD分组以及共享变量。一个应用可以串行或并行地运行多个作业,并为这些作业提供访问由同一应用的先前作业所缓存的RDD的机制。
Task:具体执行的任务,Task 分为 ShuffleMapTask 和 ResultTask 两种,分别类似于 Hadoop 中的 Map、Reduce
Job:用户提交的作业,一个 Job 可能由一到多个 Task 组成
Stage:Job 划分的阶段(stage),一个 Job 可能被划分为一到多个 stage
Partition:数据分区,一个 Rdd 数据可以划分为多个分区
NarrowDependency:窄依赖,子 RDD 依赖于父 RDD 中固定的 partition,NarrowDependency 分为 OneToOneDependency 和 RangeDependency 两种
ShuffleDependency:shuffle 依赖,也称为宽依赖,子 Rdd 对父 Rdd 中所有 Partition 都有依赖
DAG(Directed Acycle graph):有向无环图,用于描述 Rdd 之间的依赖关系
运行机制
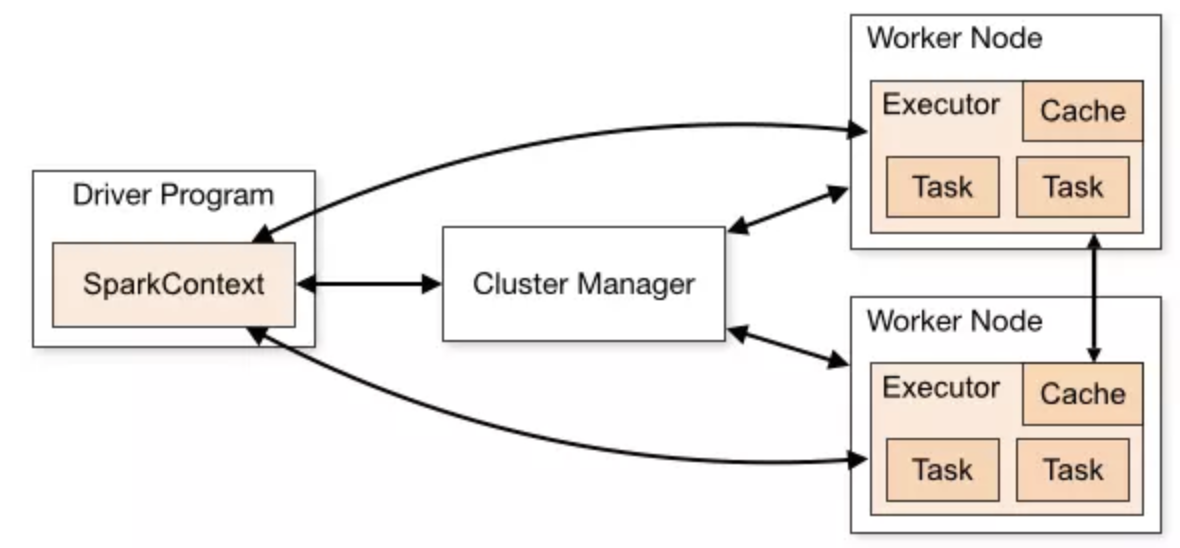
Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器
Worker节点:从节点,负责控制计算节点,启动Executor或者Driver。
Driver: 运行Application 的main()函数
Executor:执行器,是为某个Application运行在worker node上的一个进程
在最高层,spark有两个独立的实体:driver和executor。driver负责托管应用(SparkContext)并为作业调度提供任务。executor专属于应用,在应用运行期间运行,并执行该应用的任务。通常,driver作为一个不由集群管理器(cluster manager)管理的客户端来运行,而executor则运行在集群的计算机上。
作业提交
当对RDD执行一个动作(如count())时,会自动提交一个spark作业。从内部来看,它导致对SparkContext调用runJob(),然后调用传递给作为driver的一部分运行的调度程序。调度程序由两部分组成:DAG调度程序和任务调度程序。DAG调度程序把作业分解为若干阶段,并由这些阶段构成一个DAG。任务调度程序则负责把每个阶段中的任务提交到集群。
DAG的构建
stage中运行的任务分为两种类型:shuffle map和result任务。shuffle map任务类似于MapReduce中shuffle的map端部分。每个shuffle map任务在一个RDD分区上运行计算,并根据分区函数把输出写入一组新的分区中,以允许后面的stage取用(后面的阶段可能由shuffle map任务组成,也可能由result任务组成)。shuffle map任务运行在除最终阶段之外的其它所有阶段中。result任务运行在最终阶段,并将结果返回给用户程序(如count()的结果)。每个result任务在它自己的RDD分区上运行计算,然后把结果发送回driver,再由driver将每个分区的计算结果汇集成最终结果。简单的spark作业可能不需要shuffle,只有一个result任务构成stage,就像MapReduce中仅有map作业一样。
如果RDD已经被同一应用(SparkContext)中先前的作业持久化保存,那么DAG调度程序将会省掉一些工作,不会再创建stage来重新计算它或它的父RDD。
DAG调度程序负责将一个阶段分解为若干任务以提交给任务调度程序。DAG调度程序会为每个任务赋予一个位置偏好(placement preference),以允许任务调度程序充分利用数据本地化(data locality)。对于HDFS上的输入RDD分区来说,它的任务位置偏好就是托管了这些分区的数据块的datanode(称为node local),对于在内存中缓存的RDD分区,其任务的位置偏好是那些保存RDD分区的executor(称为process local)。
一旦DAG调度程序已构建一个完整的多阶段DAG,它就将每个阶段的任务集合提交给任务调度程序,子阶段只有在其父阶段成功完成后才能提交。
任务调度
当任务集合被发送到任务调度程序后,任务调度程序将该集合作为应用运行executor的列表,在斟酌位置偏好的同时构建任务到executor的映射。然后,任务调度程序将任务分配给具有可用内核的executor(如果同一应用中的另一个作业正在运行,则有可能分配不完整),并且在executor完成运行任务时继续分配更多的任务,直到任务集合全部完成。默认情况下,每个任务分配一个内核,可通过spark.task.cpus来更改。
任务调度程序在为某个executor分配任务时,首先分配的是进程本地(process local)任务,再分配节点本地(node local)任务,然后分配机架本地(rack local)任务,最后分配任意(非本地)任务或推测任务(speculative task)。
这些被分配的任务通过调度程序后端启动,调度程序后端向executor后端发送远程启动任务的消息,以告知executor开始运行任务。当任务启动或失败时,executor都会向driver发送状态更新消息。如果失败了,任务调度程序将在另一个executor上重新提交任务。若是启用了推测任务(默认不启动),它还会为运行缓慢的任务启动推测任务。
spark利用Akka(一个基于Actor的平台,akka.io/)来构建高度可扩展的事件驱动分布式应用,而不是使用Hadoop RPC进行远程调用。
任务执行
executor首先确保任务的jar包和文件依赖关系都是最新的,它在本地高速缓存中保留了先前任务已使用的所有依赖,只有在它们更新的情况下才会重新下载。然后,由于任务代码是以启动任务消息的一部分而发送的序列化字节,需要反序列化代码(包括用户自己的函数)。最后,执行任务代码,任务代码运行在与executor相同的JVM中,任务的启动没有进程开销。
执行结果被序列化并发送到executor后端,然后以状态更新消息的形式返回driver。shuffle map任务返回的是一些可以让下一阶段检索其输出分区的信息,而result任务则返回其运行的分区结果值,driver将这些结果值收集起来,并把最终结果返回给用户程序。
集群管理器
负责管理executor生命周期的是集群管理器(cluster manager),spark提供了多种不同特性的集群管理器。
本地模式
使用本地模式时,executor与driver运行在同一个JVM中,一般用于测试或小规模作业。这种模式的主URL为local(使用一个线程)、local[n](n个线程)或local(*)(机器的每个内核一个线程)
独立模式
独立模式是集群管理器的一个简单的分布式实现,它运行一个master以及一个或多个worker。当spark应用启动时,master要求worker代表应用生成多个executor进程。这种模式的主URL为spark://host:port。
Mesos模式
Apache Mesos是一个通用的集群资源管理器,它允许根据组织策略在不同的应用之间细化资源共享。默认情况下(细粒度模式),每个spark任务被当作一个Mesos任务运行。这样可以更有效地使用集群资源,但是以额外进程启动开销为代价。在粗粒度模式下,executor在进程中运行任务,spark应用运行期间的集群资源由executor进程来掌管。这种模式的主URL为mesos://host:port
YARN模式
YARN是Hadoop中使用的资源管理器,每个运行的Spark应用对应一个YARN应用实例,每个executor在自己的YARN容器中运行。这种模式的主URL为yarn-client或yarn-cluster。
Mesos和YARN集群管理器优于独立模式的集群管理器,因为它们考虑了集群上运行的其它应用(如MR作业)的资源需求,并统筹实施调度策略。此外,YARN是唯一能够与Hadoop的Kerberos安全机制集成的集群管理器。