Given n non-negative integers a1, a2, …, an, where each represents a point at coordinate (i, ai). n vertical lines are drawn such that the two endpoints of line i is at (i, ai) and (i, 0). Find two lines, which together with x-axis forms a container, such that the container contains the most water.
等值联结(内部联结),等值联结是在WHERE子句中指定两表中联结的字段:SELECT id FROM ta, tb WHERE ta.vid = tb.vid,内联结可以达到同样的效果:SELECT id FROM ta INNER JOIN tb ON ta.vid = tb.vid。ANSI SQL规范首选INNER JOIN语法。
自联结,如果需要多次使用同一个表,可以用表别名和自联结来实现:SELCT p1.proc_id, p1.proc_name FROM products AS p1, product AS p2 WHERE p1.vend_id = p2.vend_id AND p2.proc_id = “DTNTR”
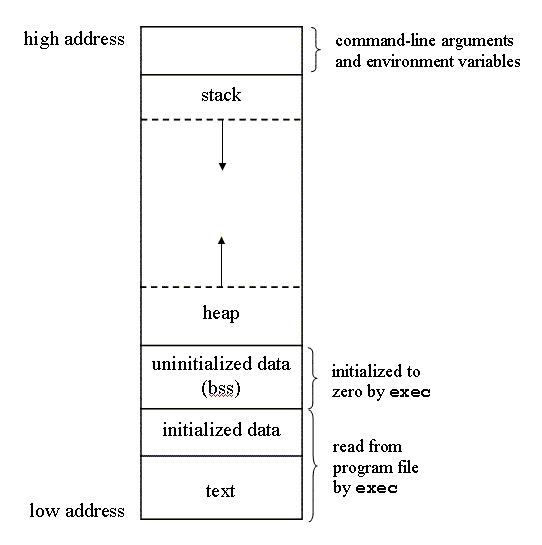
Every process has a unique ID, a non-negative integer. Process ID 0 is usually the scheduler process and is often known as the swapper. No process on disk correspons to this process, which is part of the kernel and is konwn as a system process. Process ID 1 is usually the init process and is invoked by the kernel at the end of the bootstrap procedure. The program file for this process was /etc/init in older verion of the UNIX System and is /sbin/init in newer version. This process is responsible for bringing up a UNIX system after the kernel has been bootstraped. init usually reads the system-dependent initialization files - the /etc/rc* files or /etc/inittab and the files in /etc/init.d - and brings the system to a certain state, such as multiuser. The init process never dies, it is a normal user process althrough it runs with superuser privileges.
fork function
An existing process can create a new one by calling the fork function.
1 2 3
# include<unistd.h> //Returns: 0 in child, process ID of child in parent, -1 on error pid_tfork(void);
This function is called once but return twice. The reason the child’s process ID is returned to the parent is that a process can have more than one child, and there is no function that allows a process to obtain the process IDs of its children. The reason fork returns 0 to the child is that a process can have only a single parent, and the child can always call getppid to obtain the process ID of its parent.(Process ID 0 is reserved for use by the kernelit’s not possible for 0 to by the process ID of a child).
Both the child and the parent continue executing with the instruction that follows the call to fork. The child is a copy of the parent, for example, the child gets a copy of the parent’s data space, heap, and stack. This is a copy for the child, the parent and the child do not share these portions of memory. The parent and the child share the text segment.
Modern implements don’t perform a complete copy of the parent’s data, stack and heap, since a fork is often followed by an exec. Instend, a technique called copy-on-write(COM) is used. These regions are shared by the parent and the child and have their protection changed by the kernel to read-only. If either process tries to modify these regions, the kernel then makes a copy of that piece of memeory only, typically a “page” in a virtual memory system.
All file descriptors that are open in the parent are duplicated in the child. The parent and the child share a fiel table entry for every open descriptor. There are two normal cases for handling the descriptors after a fork.
The parent waits for the child to complete. In this case, the parent docs not need to do anything with its descriptors. When the child terminates, any of the shared descriptors that the child read from or wrote to will have their file offsets updated accordingly.
Both the parent and the child go their own ways. Here after the fork, the parent closes the descriptors that it doesn’t need and the child does the same thing. This way neither interferes with the other’s open descriptors. This scenario is often found with network servers.
publicinterfacePlatformTransactionManagerextendsTransactionManager{ // Return a currently active transaction or create a new one, according to the specified propagation behavior. TransactionStatus getTransaction(@Nullable TransactionDefinition definition)throws TransactionException; // Commit the given transaction, with regard to its status. If the transaction has been marked rollback-only programmatically, perform a rollback. voidcommit(TransactionStatus status)throws TransactionException; // Perform a rollback of the given transaction. voidrollback(TransactionStatus status)throws TransactionException; }
根据底层所使用的不同的持久化 API 或框架,PlatformTransactionManager 的主要实现类大致如下: